


Как сэкономить на стоимости перевода до 50%
Иногда мы говорим нашим клиентам из компаний, что сможем благодаря повторам помочь им снизить стоимость перевода. Некоторые спрашивают, как это и что считается повторами. В этой статье я расскажу подробнее, как это делается.
Содержание
Внутрифайловые и межфайловые повторы
В каких документах обычно встречаются повторы?
А если у вас файлы PDF или картинки?
Какие программы для подсчета повторов мы используем?
Как считаются повторы
Повторы считаются специальными переводческими программами. Мы называем их САТ-программами (computer-aided translation). Одна из задач этих программ – помочь переводчику не переводить одну и ту же фразу каждый раз заново. У этих программ есть и другие полезные функции, но здесь мы будем рассматривать только одну – экономия на стоимости перевода.
Программа анализирует каждый сегмент в тексте и вычисляет процент повторяющихся сегментов. Когда переводчик вводит перевод такого сегмента и подтверждает его, программа автоматически распространяет этот перевод на все такие же сегменты. И когда переводчик идет по тексту дальше, все уже переведенные таким образом сегменты программа пропускает, то есть переводчику не надо переводить или подтверждать такие сегменты снова. Это экономит и силы, и время.
Вот здесь можно посмотреть, как выглядит статистика повторов в самых распространенных системах.
SDL Trados
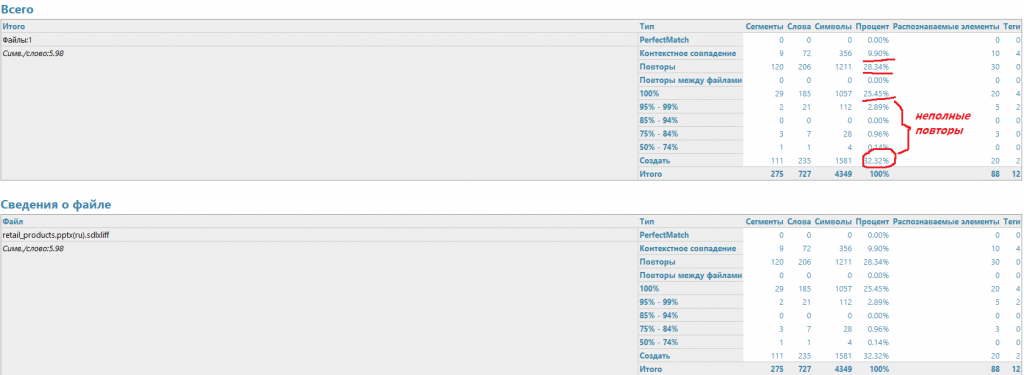
На этой картинке я выделила повторы. Если весь текст взять за 100%, то в данном файле вы увидите, что 9,90% пришлось на контекстные совпадения, 28,34% — на повторы, 25,45% — на 100% повторы и еще некоторый процент – неполные повторы (совпадения) – 1,1%. И совсем нового текста остается всего 32,32%.
Таким образом, если в данном файле, например, 1 страница, то вы оплатите всего лишь 34% от полной стоимости ее перевода. Неполные повторы оплачиваются полностью, так как их все равно надо переводить.
Smartcat
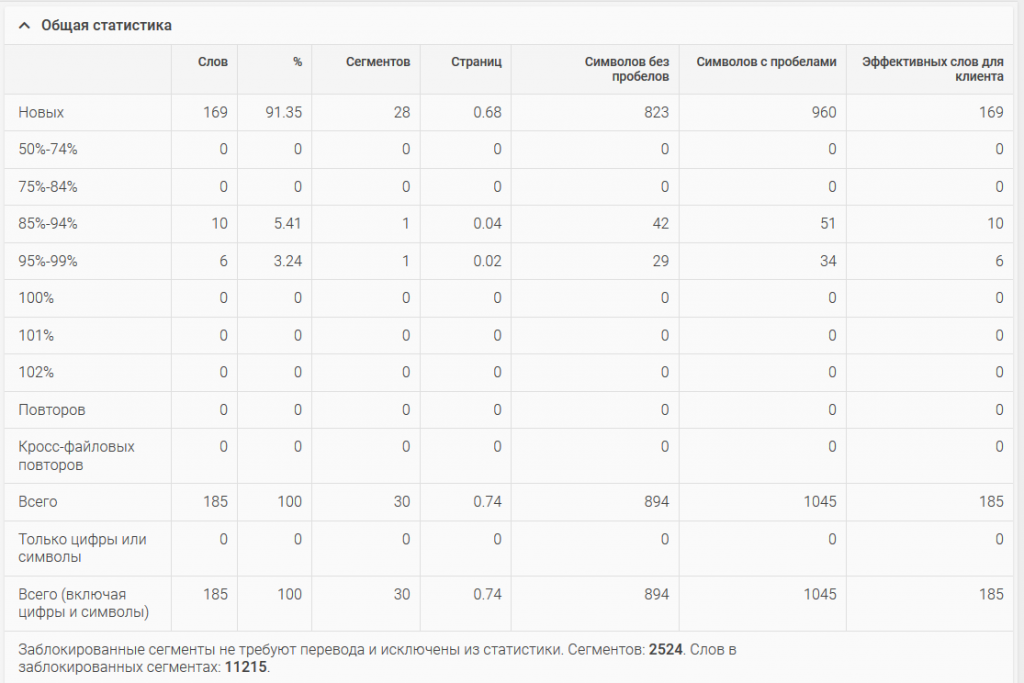
На больших проектах наличие повторов позволяет очень существенно снизить стоимость перевода.
Внутрифайловые и межфайловые повторы
Если внутри одного документа есть повторы, они называются внутрифайловыми.
Но если у вас несколько документов сразу, и одна фраза встречается в разных файлах, то такие повторы называются межфайловыми.
По нашему опыту, чаще всего встречаются межфайловые повторы. Поэтому если у вас на перевод сразу несколько файлов, мы обязательно проанализируем их на предмет повторов.
Например, на рисунке выше был проанализирован только один файл. А вот скриншот анализа пакета, состоящего из нескольких документов.
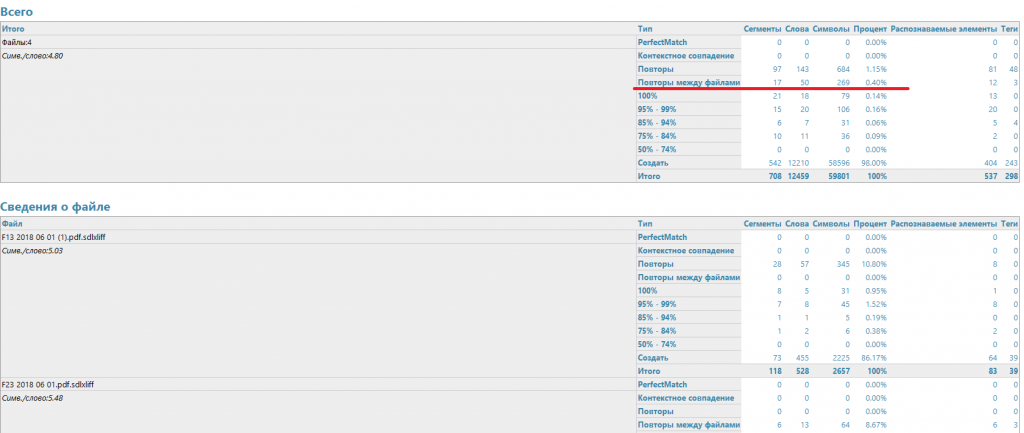
Или вот:
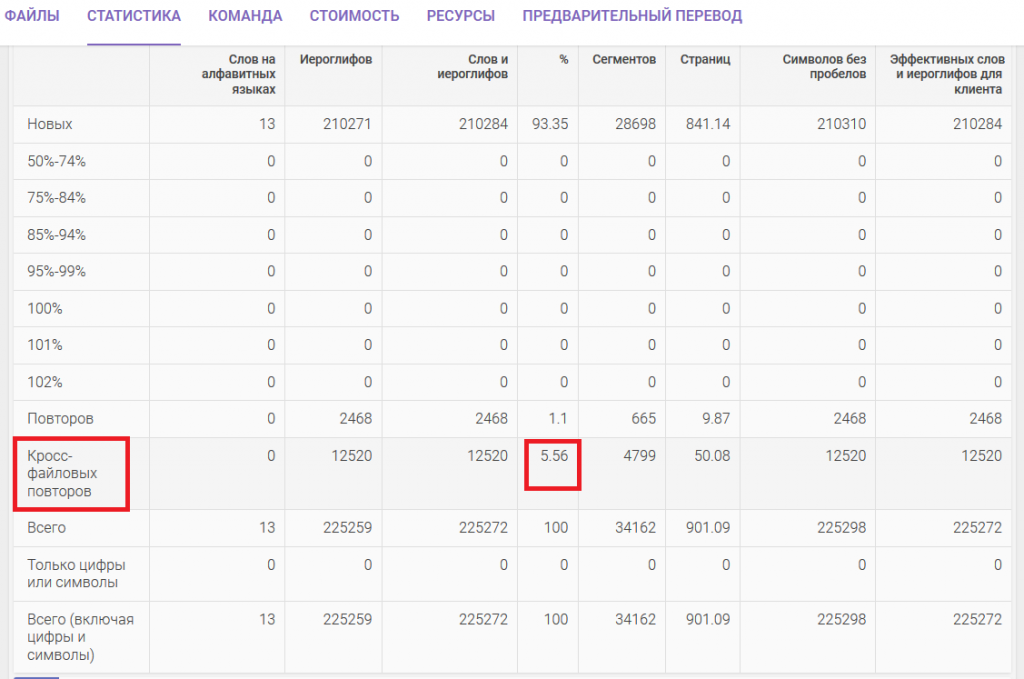
В каких документах обычно встречаются повторы?
Чаще всего повторы встречаются в следующих текстах:
— тексты для веб-сайтов
— игры
— интерфейсы
— техническая документация: описание продукции, спецификации
В каких документах повторы не встречаются или встречаются, но редко:
— статьи
— художественные и публицистические тексты
— рекламные и маркетинговые тексты
А если у вас файлы PDF или картинки?
Тут принцип таков. Если ваши файлы нормально распознаются, и программа может их обработать и посчитать повторы – никаких проблем. Если же это сканы плохого качества, которые невозможно распознать корректно, и, как следствие, проанализировать программой – тогда повторы учесть невозможно, и придется платить полную цену.
Например, вот такой файл, полученный после распознавания, программа не сможет корректно проанализировать.

А значит, его придется переводить вручную, предварительно перед этим тщательно отформатировав.
Какие программы для подсчета повторов мы используем?
В России среди переводчиков наиболее распространены SDL Trados и Smartcat. Некоторые предпочитают memoQ. Еще есть DeJa Vu, OmegaT (бесплатная), Memsource. За рубежом многие бюро переводов используют и другие программы, которые в России не особо прижились, потому что мы нашли другие более удобными, например XTM, Wordfast и другие.
Скидки на повторы
Мы даем 50% скидку на повторы. А почему, спросите вы, только 50%, а не все 100%? Ведь вроде бы повторы вводятся автоматически?
Но нельзя забывать, что мы не только переводим документ. После перевода документ проходит полную проверку редактором – все 100% независимо от количества повторов.
Зачастую проверка редактором выполняется не там же в САТ-программе, а уже в выгруженном целевом файле. Проверка выполняется по оригинальному файлу. Вот для чего это делается:
- Даже повторяющиеся сегменты проверяются полностью. Потому что одна и та же фраза в разном контексте может переводиться по-разному.
- В САТ-программе текст разбивается на отдельные сегменты, которые иногда идут не по порядку, а так, как программа их сама расположит. Например, колонтитулы, сноски, подписи к картинкам, номера страниц, примечания, комментарии идут вперемежку с основным текстом.
- При работе в САТ-программе переводчик часто переводит отдельные сегменты и не всегда имеет полную картину перевода. В этом случае перевод сегмента может звучать иначе, чем если бы переводчик переводил цельный текст без разбивки. Эта проблема решается редактором, который проверяет уже цельный перевод в полном и понятном ему контексте.
- Текст может быть некорректно распознан, содержать ошибки распознавания, битую кодировку и другие дефекты. Переводчик может этого не заметить или просто проигнорировать. Зато редактор будет проверять перевод прямо по исходнику и все это заметит и исправит.
- Часто распознанный текст разбивается в САТ-программе неверно. Например, одна часть предложения – в одном сегменте, а хвост – в другом, причем не в следующем, а через несколько сегментов. Переводчик не всегда это понимает и переводит как есть, в итоге перевод получается некорректным, а увидеть такую ошибку можно только в уже выгруженном целевом файле.
А вот здесь можно посмотреть, как мы редактируем переводы.
Вот как можно добиться существенной экономии на стоимости перевода с помощью современных технологий.
Если у вас есть пакет файлов на перевод – присылайте, мы можем их проанализировать и посчитать стоимость с учетом повторов.
Рассчитать стоимость
